Vollautomatisches Dokumentenarchiv mit Fujitsu ScanSnap und Hazel auf dem Mac
09.10.2016 | Computer & co.
Ein elektronisches Dokumentenarchiv hat einige Vorteile wie z.B. Volltextsuche und einfacher Zugriff auf Dokumente per Smartphone. Leider ist die Pflege mit einiger Arbeit verbunden. Mit modernen Methoden läßt sich zum Glück vieles automatisieren. Nachfolgend beschreibe ich wie man mit dem Scanner ScanSnap und der Mac Software „Hazel“ (https://www.noodlesoft.com) den Archivierungsprozess faßt vollständig automatisieren kann.
Hazel kann Ordner überwachen und basierend auf deren Inhalte Aktionen ausführen. Für meine Prozedur habe ich eine Ordnerstruktur angelegt, welche der Struktur des Archivierungsvorgangs folgt:
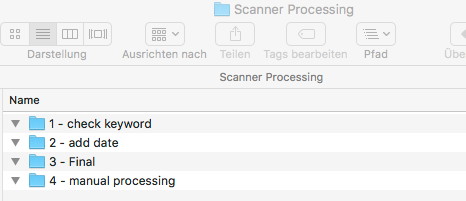
Der Ordner in dem sich alles abspielt heißt bei mir „Scanner Processing“. Hier enthalten sind Unterordner für die Hazel-Bearbeitungsschritte.
Und so läuft es:
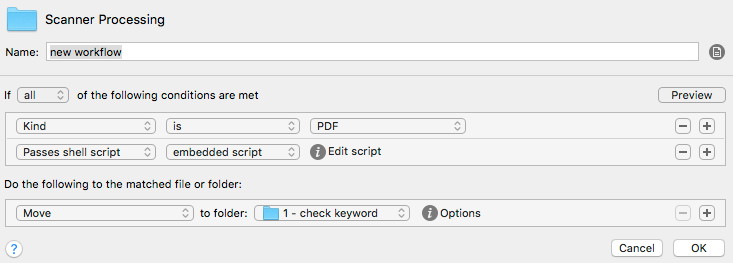
Die Fujitsu-Software ist so eingestellt, dass der Scan zunächst in der obersten Ordner-Ebene landet. Hier fängt das erste Problem an: nach dem Scan wird noch die OCR-Texterkennung durchgeführt und dann ist das PDF erst wirklich fertig. Also muss Hazel das erkennen, denn bei einem sofortigen Start würde Hazel in Konflikt mit der noch laufenden Fujitsu-Software geraden. Die Hazel Prozedur zur Lösung dieses Problems ist:
Das Shell Script ist:
#! /bin/bash
if [ `pdffonts „$1“ | grep Type | sed -n ‚$=’` ]
then
exit 1
else
exit 0
fi
Umgangssprachlich passiert: Wenn im Ordner ein PDF liegt und dieses Text enthält, dann schiebe Dokument in „1 – check keyword“ für den eigentlichen Archivierungsvorgang. Text enthält das Dokument erst nach dem OCR, also wenn die Scanner-Software fertig ist.
In der Orderüberwachung für „1 – check keyword“ habe ich ganz viele einfache Regeln, die in den Inhalt des Dokuments schauen und danach Zuordnungen vornehmen. Beispiel:
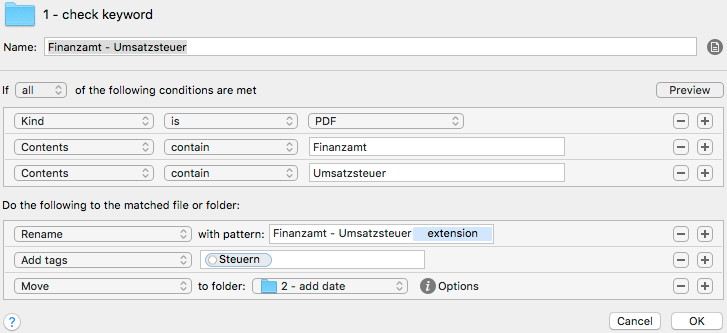
Die Regel ist: Wenn im Dokument die Worte „Finanzamt“ und „Umsatzsteuer“ vorkommen, dann benenne die Datei in „Finanzamt – Umsatzsteuer.pdf“ um, hänge das Attribut „Steuern“ an und schiebe es weiter and „2 – add date“. Das Attribut gibt den Namen des späteren Zielordners an.
Jetzt wird das Datum im Dokument gesucht, ausgelesen und im passenden Format für den Dateinamen verwendet:
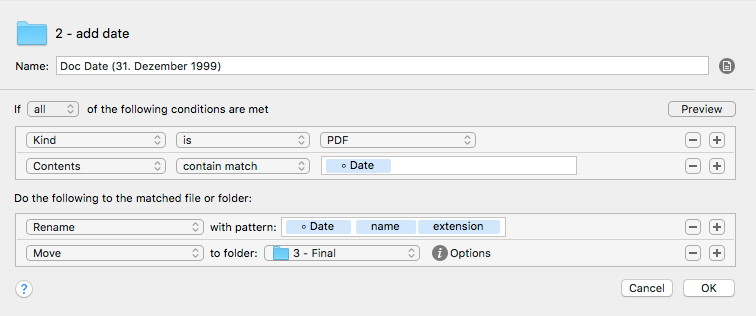
Ich habe mehrere Regeln, um verschiedene Datumsschreibweisen zu verarbeiten. Hier ist Hazel sehr mächtig weil man das einfach zusammenklicken kann:
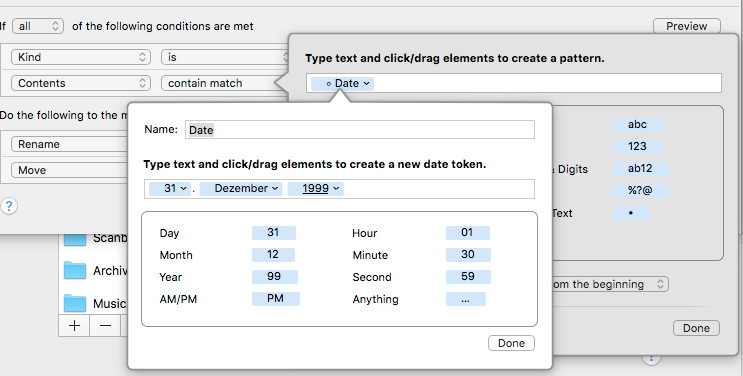
Bei mir steht das Datum immer vorne im Dateinamen. Eine andere Anordnung ist bei der Dateiumbenennung ja einfach zurechtzuschieben. Da Hazel das Datum „versteht“, kann man es für den Dateinamen in der Form ausgeben wie man es möchte, auch ganz einfach zusammenklicken:
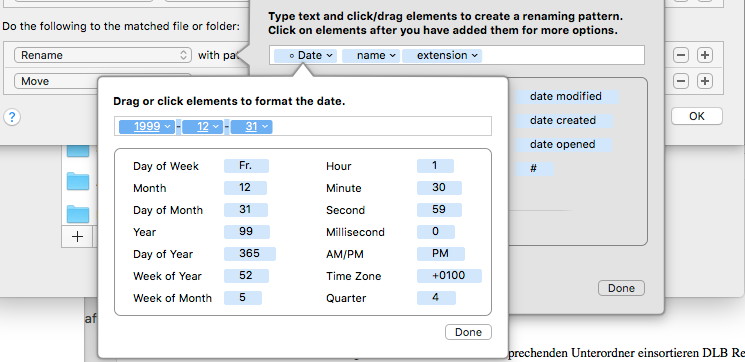
Am Ende dieser Regel wird das Dokument nach „3 – Final“ geschoben, von wo es einsortiert werden soll.
Das Einsortieren geht mit Hazel-Möglichkeiten leider nicht mit einer einzigen Regel, man braucht für jeden Zielordner jeweils eine. Das sieht dann so aus:
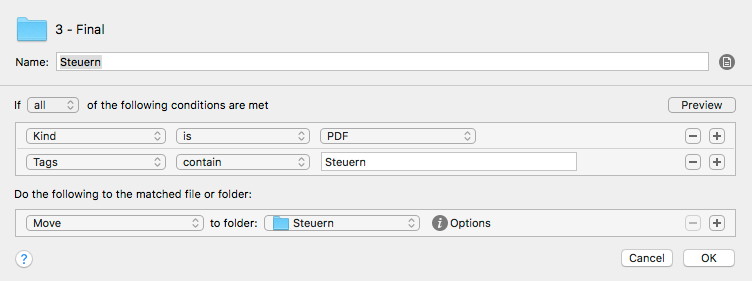
Die Regel sucht ein bestimmtes Attribut und schiebt das Dokument dann in die passende Ordnerstruktur. Wenn der Zielordner nicht existiert, wird er automatisch angelegt.
Wenn ein Dokument kein Attribut bekommen hat (kein Schlüsselwort-Treffer) oder keine Einsortier-Regel trifft, dann schiebe ich das Dokument in „4 – manual processing“. Dieses ist die letzte Regel der Ordnerüberwachung:
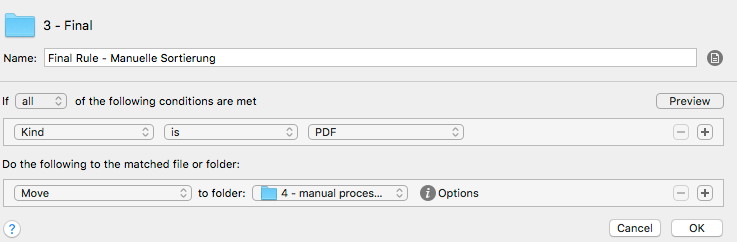
So bin ich mir sicher, dass bei dem Automatismus nichts übersehen wird und ich kann für das was da liegen bleibt meine Regeln leicht ergänzen. Da meine Ordnerstruktur sich selten ändert, muss ich in der Praxis eigentlich immer nur Schlüsselwort-Suchregeln ergänzen. Ich verändere dann einfach ein Duplikat einer vorhandenen Regel, was eine Sache von Sekunden ist.
Hazel kann Ordner überwachen und basierend auf deren Inhalte Aktionen ausführen. Für meine Prozedur habe ich eine Ordnerstruktur angelegt, welche der Struktur des Archivierungsvorgangs folgt:
Der Ordner in dem sich alles abspielt heißt bei mir „Scanner Processing“. Hier enthalten sind Unterordner für die Hazel-Bearbeitungsschritte.
Und so läuft es:
Die Fujitsu-Software ist so eingestellt, dass der Scan zunächst in der obersten Ordner-Ebene landet. Hier fängt das erste Problem an: nach dem Scan wird noch die OCR-Texterkennung durchgeführt und dann ist das PDF erst wirklich fertig. Also muss Hazel das erkennen, denn bei einem sofortigen Start würde Hazel in Konflikt mit der noch laufenden Fujitsu-Software geraden. Die Hazel Prozedur zur Lösung dieses Problems ist:
Das Shell Script ist:
#! /bin/bash
if [ `pdffonts „$1“ | grep Type | sed -n ‚$=’` ]
then
exit 1
else
exit 0
fi
Umgangssprachlich passiert: Wenn im Ordner ein PDF liegt und dieses Text enthält, dann schiebe Dokument in „1 – check keyword“ für den eigentlichen Archivierungsvorgang. Text enthält das Dokument erst nach dem OCR, also wenn die Scanner-Software fertig ist.
In der Orderüberwachung für „1 – check keyword“ habe ich ganz viele einfache Regeln, die in den Inhalt des Dokuments schauen und danach Zuordnungen vornehmen. Beispiel:
Die Regel ist: Wenn im Dokument die Worte „Finanzamt“ und „Umsatzsteuer“ vorkommen, dann benenne die Datei in „Finanzamt – Umsatzsteuer.pdf“ um, hänge das Attribut „Steuern“ an und schiebe es weiter and „2 – add date“. Das Attribut gibt den Namen des späteren Zielordners an.
Jetzt wird das Datum im Dokument gesucht, ausgelesen und im passenden Format für den Dateinamen verwendet:
Ich habe mehrere Regeln, um verschiedene Datumsschreibweisen zu verarbeiten. Hier ist Hazel sehr mächtig weil man das einfach zusammenklicken kann:
Bei mir steht das Datum immer vorne im Dateinamen. Eine andere Anordnung ist bei der Dateiumbenennung ja einfach zurechtzuschieben. Da Hazel das Datum „versteht“, kann man es für den Dateinamen in der Form ausgeben wie man es möchte, auch ganz einfach zusammenklicken:
Am Ende dieser Regel wird das Dokument nach „3 – Final“ geschoben, von wo es einsortiert werden soll.
Das Einsortieren geht mit Hazel-Möglichkeiten leider nicht mit einer einzigen Regel, man braucht für jeden Zielordner jeweils eine. Das sieht dann so aus:
Die Regel sucht ein bestimmtes Attribut und schiebt das Dokument dann in die passende Ordnerstruktur. Wenn der Zielordner nicht existiert, wird er automatisch angelegt.
Wenn ein Dokument kein Attribut bekommen hat (kein Schlüsselwort-Treffer) oder keine Einsortier-Regel trifft, dann schiebe ich das Dokument in „4 – manual processing“. Dieses ist die letzte Regel der Ordnerüberwachung:
So bin ich mir sicher, dass bei dem Automatismus nichts übersehen wird und ich kann für das was da liegen bleibt meine Regeln leicht ergänzen. Da meine Ordnerstruktur sich selten ändert, muss ich in der Praxis eigentlich immer nur Schlüsselwort-Suchregeln ergänzen. Ich verändere dann einfach ein Duplikat einer vorhandenen Regel, was eine Sache von Sekunden ist.